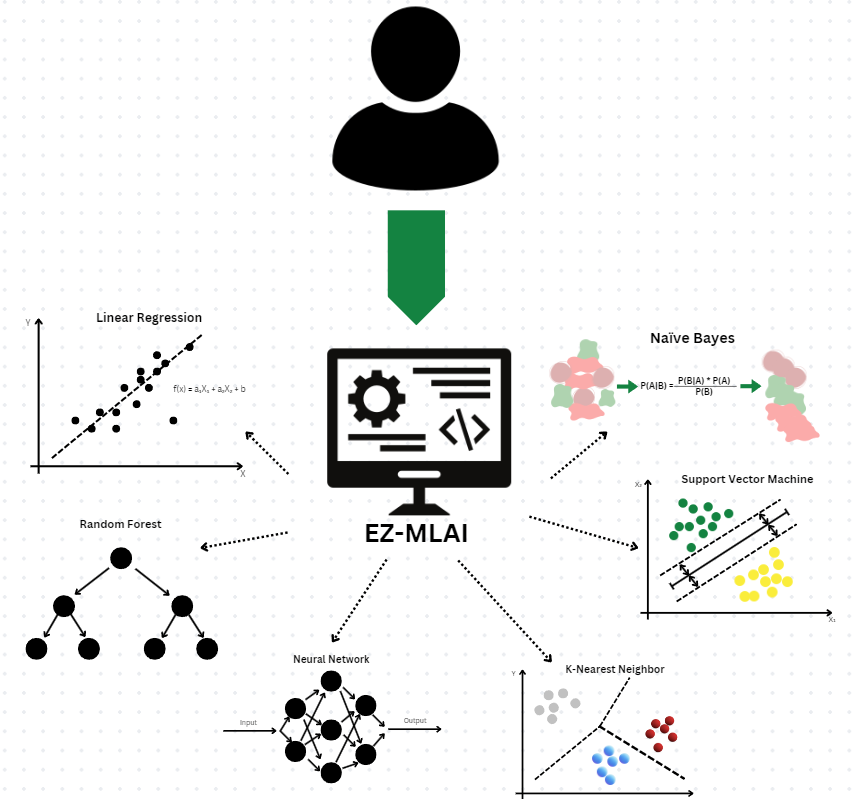
Want to use AI, but don't know how to code? Or are you an experienced coder who doesn't want to be hassled with intricacies?
Then EZ-MLAI is for you. You can customize machine-learning models for an assortment of the most popular models and get model metrics in graphs and digits, all with just a dataset and no coding
EZ-MLAI provides various accommodations and allows for easy machine-learning model building. All you need is a dataset that fits the model parameters listed under each specific model. We provide choices from a list of the 6 most popular Machine Learning algorithms to choose from to build your model. Build Your Novel Machine Learning Model Today.
Explore our machine-learning models by navigating to the Models page and learn more about key vocab from the Model Descriptions page.
Data and the corresponding Models that you should use:
Fully numerical data: Multiple Linear Regression
A mix of numerical and categorical independent variables and numerical dependent variable: Random Forest
Image data: Neural Network
A mix of numerical and categorical independent variables and categorical dependent variables: Either K-Nearest-Neighbor or Naive Bayes
Fully numerical independent variables and numerical class dependant variables: Support Vector Machine
EZ-MLAI
EZ-MLAI
Easy Access to Machine Learning AI
No Matter Your Experience Level
About Us
CEO and Founder of EZ-MLAI
My name is Kadhir Ponnambalam and I am an enthusiastic data scientist. I want to help share knowledge on Machine Learning and have data science applicable to as many people as possible. My mission is to provide those with little to no coding experience access to a technology that was previously exclusive to coders. In addition, I want experienced coders to be able to approach Machine Learning without the need for all the hard work. I hope that my application can be used by everybody in hopes of further development in applying this technology.
Design Consultant:
Kavya Muralikumar
Model, Metrics, and Visualization Descriptions
Linear Regression
Linear regression is a statistical method that models the relationship between a dependent variable and one or more independent variables.
Metrics:
MSE (Mean Squared Error): Measures the average squared difference between actual and predicted values.
MAE (Mean Absolute Error): Measures the average absolute difference between actual and predicted values.
RMSE (Root Mean Squared Error): Measures the square root of the average squared difference between actual and predicted values.
EVS (Explained Variance Score): Measures the proportion of variance explained by the model.
R-squared: Measures the proportion of variance in the dependent variable that is predictable from the independent variables.
Adjusted R-squared: Adjusts the R-squared value for the number of predictors in the model.
Equation of Model: The mathematical representation of the relationship between dependent and independent variables.
Visualizations:
Predicted vs Actual: Plot the predicted values against the actual values to assess the model's accuracy.
Residual Plot: Shows the residuals (errors) between the actual and predicted values.
Q-Q Plot: Compares the distribution of the residuals to a normal distribution.
Distribution of Data Histograms: Displays the distribution of each variable in the dataset.
Scatter Plot of Data vs Dependent Variable: Plots each independent variable against the dependent variable to visualize relationships.
Loss Chart: Shows the loss value over iterations during training.
Random Forest
Random forest is an ensemble learning method for classification, regression, and other tasks, that operates by constructing multiple decision trees.
Metrics:
MSE (Mean Squared Error): Measures the average squared difference between actual and predicted values.
MAE (Mean Absolute Error): Measures the average absolute difference between actual and predicted values.
RMSE (Root Mean Squared Error): Measures the square root of the average squared difference between actual and predicted values.
R-squared: Measures the proportion of variance in the dependent variable that is predictable from the independent variables.
Adjusted R-squared: Adjusts the R-squared value for the number of predictors in the model.
MAPE (Mean Absolute Percentage Error): Measures the average absolute percentage difference between actual and predicted values.
Explained Variance Score: Measures the proportion of variance explained by the model.
Visualizations:
Feature Importance: Shows the importance of each feature in the model.
Partial Dependence: Plots the marginal effect of a feature on the predicted outcome.
Residuals: Shows the residuals (errors) between the actual and predicted values.
Actual vs Predicted: Plots the predicted values against the actual values to assess the model's accuracy.
Distribution of Numeric Data: Displays the distribution of numeric variables in the dataset.
Neural Network
Neural networks are a set of algorithms, modeled loosely after the human brain, that are designed to recognize patterns.
Metrics:
Accuracy: Measures the proportion of correct predictions.
Visualizations:
Confusion Matrix: Shows the performance of the classification model by comparing actual and predicted labels.
Loss Chart per Epoch: Displays the loss value over epochs during training.
Training and Validation: Compares the training and validation performance metrics.
Weights and Biases: Visualizes the learned weights and biases in the network.
Distribution of Data: Displays the distribution of the data used for training and testing the model.
K-Nearest Neighbour
K-nearest neighbour is a non-parametric method used for classification and regression by comparing the closest training examples in the feature space.
Metrics:
Accuracy: Measures the proportion of correct predictions.
Precision: Measures the proportion of true positive predictions among all positive predictions.
Recall: Measures the proportion of true positives identified correctly.
F1 Score: The harmonic mean of precision and recall.
AUC-ROC: Measures the ability of the model to distinguish between classes.
Average Precision: Summarizes the precision-recall curve as the weighted mean of precisions achieved at each threshold.
Visualizations:
Confusion Matrix: Shows the performance of the classification model by comparing actual and predicted labels.
Predicted vs Actual: Plots the predicted values against the actual values to assess the model's accuracy.
ROC Curve: Displays the performance of the classification model at all classification thresholds.
Precision-Recall Curve: Shows the trade-off between precision and recall for different threshold values.
Data Distribution: Displays the distribution of data used in the model.
Support Vector Machine
Support vector machine is a supervised learning model that analyzes data for classification and regression analysis by finding the hyperplane that best separates the data into classes.
Metrics:
Accuracy: Measures the proportion of correct predictions.
Precision: Measures the proportion of true positive predictions among all positive predictions.
Recall: Measures the proportion of true positives identified correctly.
F1 Score: The harmonic mean of precision and recall.
Visualizations:
Predicted vs Actual: Plots the predicted values against the actual values to assess the model's accuracy.
Confusion Matrix: Shows the performance of the classification model by comparing actual and predicted labels.
ROC Curve: Displays the performance of the classification model at all classification thresholds.
Precision-Recall Curve: Shows the trade-off between precision and recall for different threshold values.
Data Distribution: Displays the distribution of data used in the model.
Naive Bayes
Naive Bayes is a family of simple probabilistic classifiers based on Bayes' theorem with strong independence assumptions between the features.
Metrics:
Accuracy: Measures the proportion of correct predictions.
Precision: Measures the proportion of true positive predictions among all positive predictions.
Recall: Measures the proportion of true positives identified correctly.
F1 Score: The harmonic mean of precision and recall.
Visualizations:
Confusion Matrix: Shows the performance of the classification model by comparing actual and predicted labels.
ROC Curve: Displays the performance of the classification model at all classification thresholds.
Precision-Recall Curve: Shows the trade-off between precision and recall for different threshold values.
Distribution of Data: Displays the distribution of data used in the model.
×
×
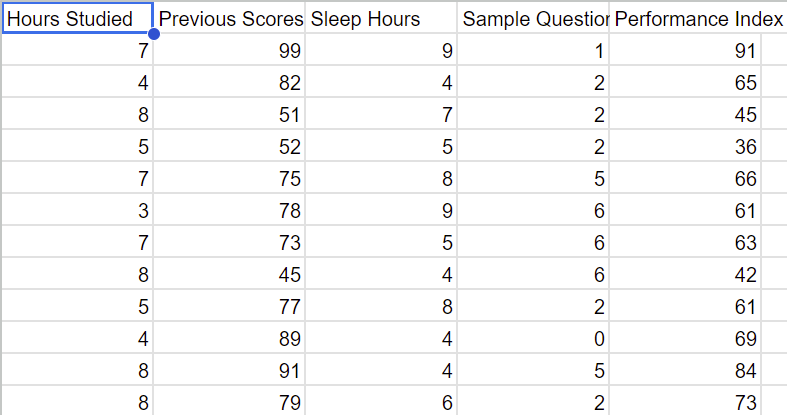
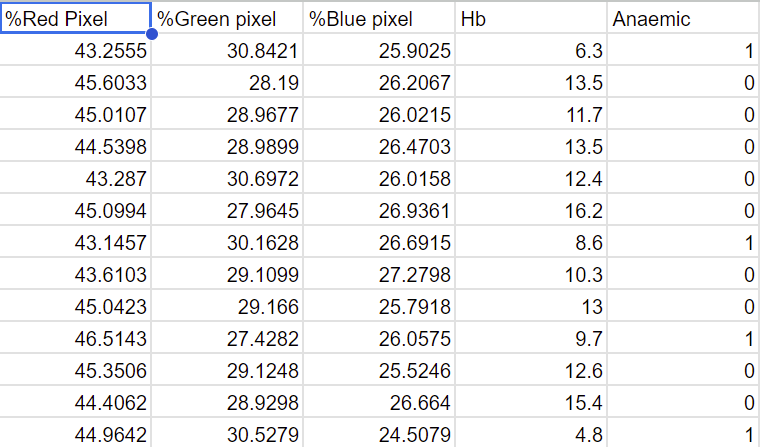
Upload CSV for Linear Regression
Checklist for Data Input(Must do):
First row must be labels(Strings)
Following rows must be numerical data
All columns excluding last must be independent variable
Last column must be dependent variable(What you are trying to predict)
Example Dataset
×
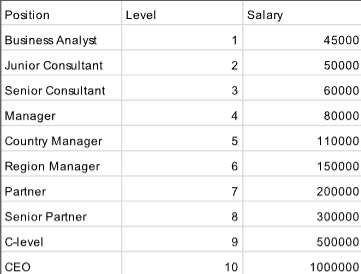
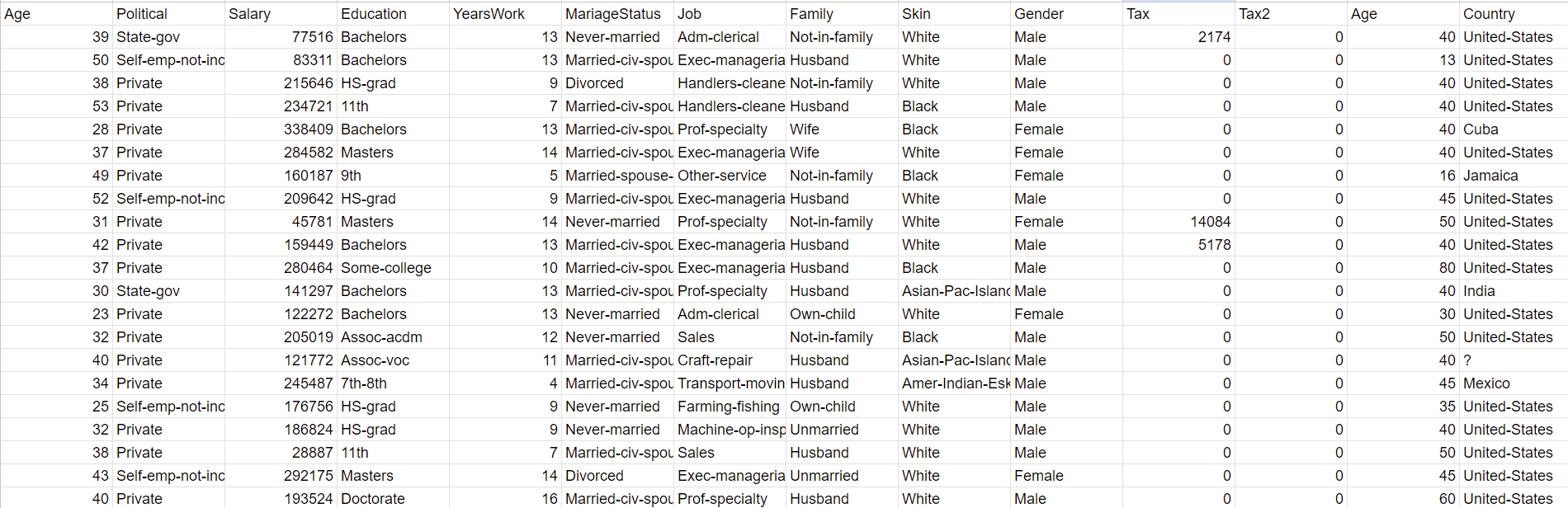
Upload CSV for Random Forest
Checklist for Data Input(Must do):
First row must be labels(Strings)
The first X number of columns you select using the slider must be categorical(String) data
Following columns must contain numerical data whether independant or dependant variable
All columns exluding last must be independant variable
Last column must be a numerical dependant variable(What you are trying to predict)
Example Dataset
0.8
×
Upload Folders of Pictures for Neural Network
Checklist for Data Input(Must do):
Name the categegory corresponding to the classification you wish to use
Click on the Drop Files box to upload pictures in that category and use Control/Command A to select multiple
images to upload into this container
To add mulitple extra categories, press the Add Category button
Have at least 2 different image categories for best results
Example Dataset
0.8
×
Upload CSV for K-Nearest-Neighbor
Checklist for Data Input (Must do):
First row must be the labels to the independant and dependant variables
Independant variables can be any combination of numerical or string categorical data
All columns excluding last must be independent variables
Last column must be dependent variable (What you are trying to predict)
Last column must be categorical data for classification algorithm
Example Dataset
×
Upload CSV for Support Vector Machine
Checklist for Data Input (Must do):
First row must be labels (Strings) for independant and dependant variables
Following rows must be numerical data
All columns excluding last must be independent variables(Numerical)
Last column must be numerical class dependent variable (What you are trying to predict)
Example Dataset
×
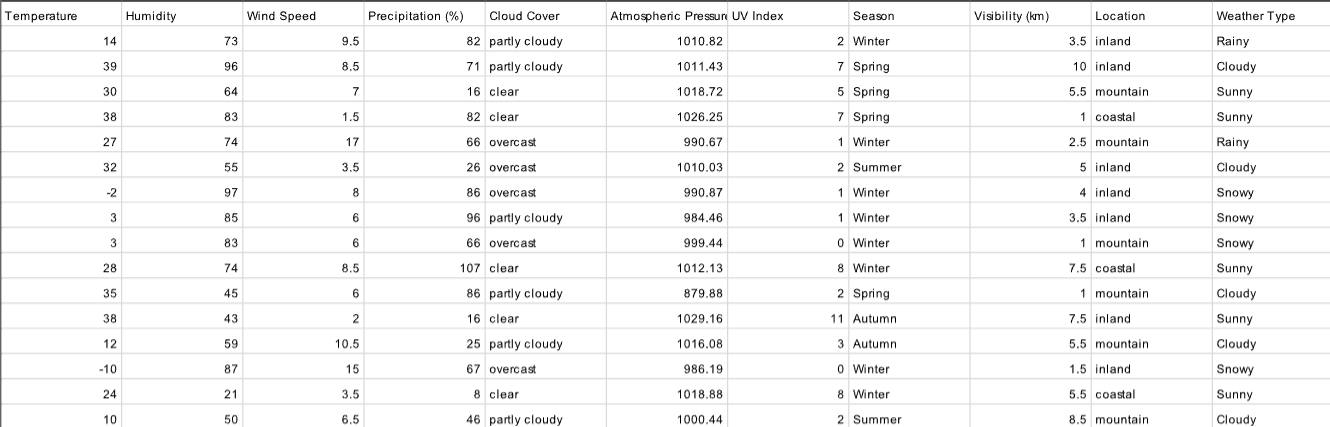
Upload CSV for Naive Bayes
Checklist for Data Input (Must do):
First row must be labels (Strings) of indpendant and dependant variables
Following rows can be any combination of String categorical or numerical data
All columns excluding last must be independent variables(any combination of String categorical and numerical data)
Last column must be String categorical dependent variable (What you are trying to predict)
Example Dataset
Loading...
Please wait while the model is being generated.
×
Multiple Linear Regression Model Report
Model was calculated once using a singular configuration of the data. Check using the python code provided for
extra clarity on the model and find average scores by running model mulitple times using same data.
×
Random Forest Model Report
Model was calculated once using a singular configuration of the data. Check using the python code provided for
extra clarity on the model and find average scores by running model mulitple times using same data.
×
Neural Network Model Report
Model was calculated once using a singular configuration of the data. Check using the python code provided for
extra clarity on the model and find average scores by running model mulitple times using same data.